The 3-Billion-Line Legacy Codebase
If you spend any time looking at how gene expression actually works, you realize that a genome isn’t a blueprint at all. It’s a legacy codebase.

People often say the genome is a “blueprint” for a human being. This is a mistake. Blueprints are static, spatial, and mostly honest. If you look at a blueprint for a house, a door is a door, and it stays where you put it.
The genome is nothing like that. If you spend any time looking at how gene expression actually works, you realize that a genome isn’t a blueprint at all. It’s a legacy codebase.
And not just any codebase. It’s a three-billion-line monorepo that hasn’t been refactored in a hundred million years.
The Infrastructure: Chromatin and the File System
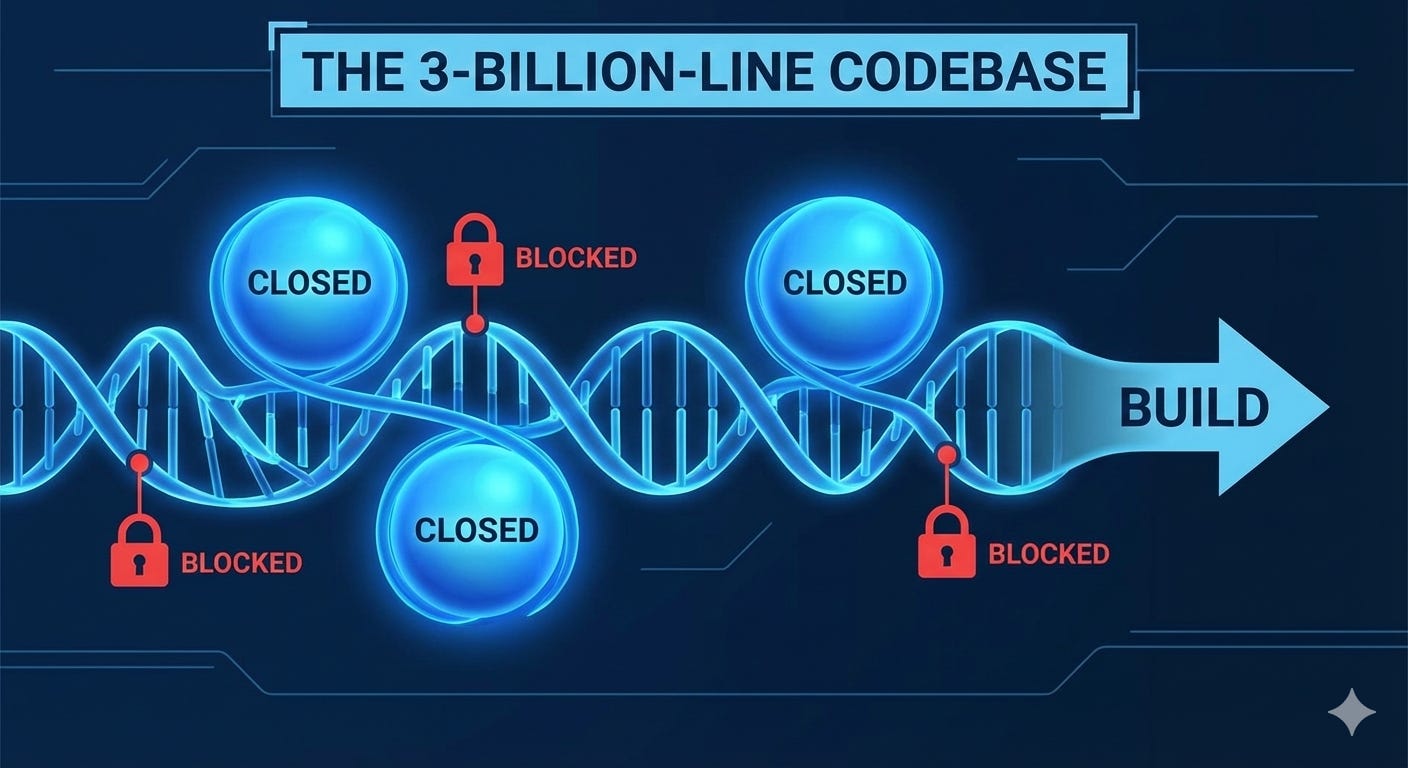
Before you can even talk about the code, you have to talk about the file system. In a computer, if a file exists on disk, the CPU can generally read it. In biology, existence does not imply accessibility.
The DNA is wrapped around proteins called histones, forming a structure called chromatin. This is the cell’s version of a compression and indexing system. When chromatin is “closed” (heterochromatin), it’s like a directory that has been zipped, encrypted, and moved to deep cold storage. The “build” machinery literally cannot physically reach the genes inside.
When the cell needs a specific set of functions, it modifies those histones—essentially adding metadata tags that tell the system to “unzip” that specific folder. This “open chromatin” state is the prerequisite for any code execution. If the infrastructure isn’t configured to expose the directory, the genes inside might as well not exist.
Hardened Permissions and Config Drift
Once a directory is open, you hit the next layer: Methylation. If chromatin is the file system, methylation is the chmod command. It’s a way of marking specific genes with “Read Only” or “Execute Denied” permissions.
What’s fascinating is that these permissions aren’t static. They are the primary way we define cell types. Every cell in your body has the same repo, but a neuron has “Execute” permissions on a totally different set of modules than a skin cell.
But here’s the problem every DevOps engineer recognizes: Config Drift. As we age, these methylation patterns start to degrade. Permissions that were supposed to stay “Off” for sixty years suddenly flip “On.” This is biological “bit rot.” One of the leading theories of aging is simply that the cell loses its ability to maintain its original permission set. The “environment” becomes cluttered with legacy processes that should have stayed dormant, leading to the system-wide instability we call senescence.
The Build System: Splicing and Build Variants
Even after a gene is “read,” we don’t just run the raw text. We go through the “Build” step: Splicing.
In a simple codebase, one file equals one executable. In the human genome, we use alternative splicing. We have these segments called exons (the code) and introns (the “junk” or scaffolding between the code). Depending on which cell type is doing the “building,” the cell will pick and choose which exons to stitch together.
A single gene in a neuron might be compiled into one protein, while in a liver cell, that same gene is compiled into something totally different. This is how humans achieve complexity without needing more genes. We don’t have more source code than a roundworm; we just have much more sophisticated build variants. We’re using the same source files to generate a massive, context-dependent library of different binaries.
The Post-Readability Era
We are currently obsessed with “Agentic AI.” We talk about MCP (Model Context Protocol) to help models talk to tools, and we’re building “skills” for agents so they can execute tasks autonomously. We think we’re designing a new kind of software architecture.
But if the genome is any indication, we’re actually just in the “Hello World” phase of a very different journey.
In our current world, we still value readability. We want to be able to open a Python file and understand what it does. But as agents begin to write their own protocols—as they start to “splice” together their own sub-routines and optimize their own context windows—we are moving toward a Post-Readability Era.
The human genome is what happens when you let agentic systems optimize for billions of years without a human code reviewer. It’s a system where the “Model” (the cell) has a “Context Protocol” (signaling pathways) so complex that it takes a PhD to understand a single “API call” between two proteins.
We see MCP as a way to connect an LLM to a database. Biology sees it as a way to connect a billion sensors to a trillion actuators in real-time. In the genome, “skills” aren’t just functions; they are modular protein domains that can be swapped, hidden, or duplicated based on the “environmental prompt” the cell receives.
The “end state” of our current AI trajectory isn’t a cleaner, more organized version of GitHub. It’s a biological soup. It’s a system where the “code” is so dense, so intertwined with its own metadata, and so context-dependent that it becomes indistinguishable from the hardware it runs on.
We are currently building the intermediate design choices—the clunky protocols and the basic agent loops. We think we’re in control because we can still read the logs. But the genome suggests that the more successful a system is at surviving in a complex environment, the less “readable” it becomes to an outside observer. Eventually, the agents won’t be writing code for us to approve. They’ll be writing code for other agents to execute, using protocols we didn’t design, optimized for goals we can only vaguely define.
We aren’t just building better software. We are witnessing the birth of a new kind of biology. If you want to know what “Production” looks like in 2050, don’t look at a clean IDE. Look at a sequence of junk DNA. It’s messy, it’s opaque, and it works better than anything we’ve ever written.
Technical Appendix: The Engineer’s Guide to Bio-Syntax
Chromatin (Open/Closed) ≈ File System Mounting: This determines if a directory is even accessible to the compiler. “Open” chromatin is mounted and ready for Read/Write; “Closed” chromatin is unmounted and archived.
Histone Modification ≈ Metadata / Indexing Tags: These act as epigenetic “Post-it notes” on the DNA. They tell the cell’s machinery whether to unzip a specific folder or compress it into deep storage.
Methylation ≈ Access Control (chmod): These are persistent chemical bits that flip permissions. Changes in methylation drive differentiation (setting the config for a specific cell type) and aging (gradual config drift or “bit rot”).
Alternative Splicing ≈ Conditional Compilation: This is the use of
#ifdeflogic to stitch together different exons. It allows the cell to create multiple specialized binaries (isoforms) from a single source file.Protein Domain ≈ Reusable Library / Module: A functional unit of code with a stable, predictable interface. Evolution “refactors” the genome by swapping these domains between different proteins to create new features.
Epigenetic Drift ≈ Config Drift / Bit Rot: This is the gradual loss of the original deployment settings over time. It is a primary root cause of aging, as the system loses the ability to keep specific genes “locked.”
Exon vs. Intron ≈ Code vs. Scaffolding: Exons are the actual code blocks that ship in the final binary. Introns are the internal structural notes and build-logic that are stripped out during the “build” process.